안녕하세요 이번에는 pytorch를 이용해서 머신러닝을 하는 방법에 대해서 정리해보려고 합니다.
pytorch는 최근 머신러닝을 하는 사람들이 많이 사용하는 프레임워크입니다.
머신러닝은 크게 세가지 단계로 이루어져있습니다.
순전파, 손실계산, 역전파
이 과정을 pytorch를 사용해서 간단히 해보려고 합니다.
텐서(Tensor)
pytorch로 머신러닝을 하기 위해서는 텐서(tensor)라는 개념을 알아야합니다.
텐서는 데이터들을 gpu에게 효과적으로 전달하여 학습하기 쉽게 만든 데이터 구조라고 생각하면 됩니다.
다음과 같은 코드로 여러 종류의 텐서를 만들 수 있습니다.
import torch
scalar = torch.tensor(3.14)
vector = torch.tensor([1,2,3])
matrix = torch.randn(2,3) # 2X3 텐서 생성
zero_matrix = torch.zeros(3,3)
one_matrix = torch.ones(2,2)
순전파
순전파란 머신러닝의 모델이 입력값을 받고 예측값을 내놓는 것입니다.
x라는 입력값을 넣으면 예측값 y = F(x)를 내놓는 것과 같습니다.
다만, 머신러닝의 F(x)는 여러 계층이 있고 가중치와 편향으로 이루어져 있다는 것이 다릅니다.
가장 간단한 선형 모델을 예로 들면 F(x) = W * x + b 와 같습니다.
W(weight)가 가중치고 b (bias)가 편향입니다.
이 내용을 pytorch 코드로 확인해보겠습니다.
import torch
x = torch.tensor([2.0])
y = torch.tensor([4.0])
import matplotlib.pyplot as plt
plt.scatter([x.item()], [y.item()], color='red')
plt.show()
이렇게 입력값이 2일 때 출력값이 4인 데이터가 있습니다.
우리는 선형모델을 준비하고 그 모델의 출력값을 계산해봅니다.
W = torch.tensor([1.0], requires_grad=True)
b = torch.tensor([1.0], requires_grad=True)
y_pred = W*x + b
x_vals = torch.linspace(0, 3, 10)
y_initial = W.detach() * x_vals + b.detach()
plt.figure(figsize=(6, 4))
plt.plot(x_vals, y_initial)
plt.scatter([x.item()], [y.item()], color='red')
plt.scatter([x.item()], [y_pred.item()], color='green')
plt.show()

위의 코드에서는 가중치와 편향을 1로 초기화 했습니다.
이렇게 한 이유는 보기좋게 그래프를 그리려고 한 것이고 이런 파라미터는 랜덤값으로 초기화 하는게 일반적입니다.
그래프에서 초록색 점이 순전파로 선형 모델이 나타낸 예측값입니다.
열심히 예측은 한 것 같은데 전혀 값이 다르네요.
머신러닝은 순전파, 손실함수 계산, 역전파 과정을 수없이 반복하면서 알맞는 값을 예측하게 됩니다.
가중치와 편향을 선언할 때 requires_grad 옵션을 쓴 이유는 pytorch가 자동으로 파라미터 기울기를 계산하게 하기 위해서입니다.
손실 계산
손실을 계산한다는 것은 모델의 오차를 계산하는 것을 의미합니다.
계산된 손실값은 파라미터를 업데이트하는데 쓰입니다. 여기서는 가중치와 편향값이 업데이트 됩니다.
손실함수에도 여러 종류가 있으며 해결하려는 문제에 따라 다르게 사용합니다.
여기서는 평균 제곱 오차 (MSE : mean square error)를 사용하도록 하겠습니다.
loss = 0.5 * (y - y_pred) ** 2
print(loss)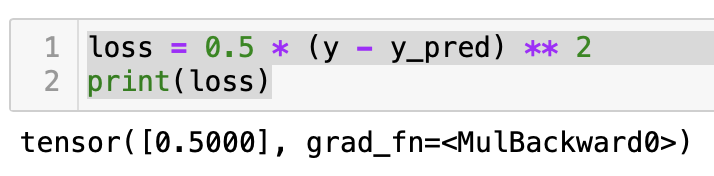
손실 값이 0.5입니다. 이 값을 줄여 나가는 방법으로 파라미터를 업데이트할 예정입니다.
역전파
역전파 과정은 손실 값을 기준으로 파라미터를 업데이트하는 과정입니다.
파라미터 업데이트 하는 과정도 여러 가지 방법이 있습니다.
여기서는 경사하강법으로 어떻게 하는 지 간단하게 보여드리겠습니다.
loss.backward()
print(W.grad.item())
print(b.grad.item())
learning_rate = 0.1
W.data -= learning_rate * W.grad
b.data -= learning_rate * b.grad
y_updated = W.detach() * x_vals + b.detach()
plt.figure(figsize=(6, 4))
plt.plot(x_vals, y_initial, linestyle="--")
plt.plot(x_vals, y_updated, color="orange")
plt.scatter([x.item()], [y.item()], color='red')
plt.show()
원래 파라미터가 변화되는 방향 (증가 혹은 감소)를 알기 위해서는 손실 함수를 편미분해서 기울기를 알아내야 합니다.
그러나 pytorch를 사용하면 자동으로 기울기를 계산해줍니다.
learning_rate는 말 그대로 학습률입니다. 한번 순전파->손실계산->역전파가 일어날 때 얼마나 파라미터를 조정할 지에 대한 값입니다.
이런 값은 계산과정에 따라 지속적으로 변하는 파라미터와 다르게 사용자 마음대로 정하는 숫자로 하이퍼 파라미터라고 합니다.

학습률이 0.1이라서 기울기 값에 0.1을 곱한만큼 변화가 되었습니다.
오렌지 색이 새로 바뀐 모델 예측선인데요. 아까보다 좀 더 실제 값에 가깝게 바뀌었습니다.
이런식으로 학습을 반복하다보면 원하는대로 입력값이 2일 때 4를 예측할 수 있게 됩니다.
우리가 실제로 사용할 모델과 학습 데이터는 이것보다 훨씬 복잡합니다.
이번에는 개념만 이해할 수 있도록 간단한 예시를 적어보았습니다.
다음에는 더 심화된 내용으로 찾아오겠습니다.
감사합니다.
'학습 > 머신러닝' 카테고리의 다른 글
| Jupyter notebook 사용법과 단축키 (0) | 2025.05.19 |
|---|---|
| 머신러닝 찍먹하기 (0) | 2024.11.08 |
| 머신러닝 공부를 위한 링크 모음 (2) | 2017.08.08 |
| [머신러닝] TensorFlow 설치 (0) | 2017.07.18 |