https://cs231n.github.io/neural-networks-2/
CS231n Deep Learning for Computer Vision
Table of Contents: Setting up the data and the model In the previous section we introduced a model of a Neuron, which computes a dot product following a non-linearity, and Neural Networks that arrange neurons into layers. Together, these choices define the
cs231n.github.io
이번에는 위 내용을 한글로 정리해보겠습니다.
데이터와 모델 설정하기
이전 섹션에서는 뉴런 모델을 소개했다.
이번 섹션에서는 데이터 전처리와 가중치 초기화 그리고 손실 함수에 대해 추가적인 디자인 선택지에 논의한다.
데이터 전처리 (Data Preprocessing)
데이터 행렬 X에 대한 데이터 전처리의 형태는 3개가 있다.
행렬 X는 [N x D] 사이즈라 가정한다. N은 데이터 개수, D는 차원
- 평균 제거(Mean Subtraction, Zero-centering): 각 특성(feature)별로 평균을 계산해 빼면 데이터 뭉치가 원점(0)을 중심으로 분포하게 되어 학습 안정성이 증가한다.
- 정규화(Normalization): 특성별 표준편차로 나누거나(min–max 스케일링) 최솟값·최댓값을 –1과 1로 맞추어 입력 스케일을 균일하게 한다.
- PCA 및 Whitening:
- 공분산 행렬의 고유분해를 통해 주요 분산 방향으로 회전(PCA) → 차원 축소 가능.
- Whitening은 PCA 후 각 축을 고유값으로 나누어 모든 방향 분산을 1로 균등화하나
작은 분산 축의 노이즈가 과장될 수 있어 주의가 필요하다.
가중치 초기화 (Weight Initialization)
가중치 초기화를 할 경우 주의해야할 사항에 대해서 정리한다.
- 0 초기화 금지: 모든 뉴런이 동일한 업데이트를 받아 학습이 정체되기 때문에 0으로 초기화 하지 않는다.
- 작은 난수 초기화: Gaussian(0, 1)에서 뽑은 난수에 1/√n, 1/n 등의 스케일을 곱해 분산을 조절하여 대칭을 깨뜨린다.
- Xavier/Glorot 초기화: 분산을 2/(nₙᵢₙ + nₒᵤₜ)로 설정
- He 초기화: ReLU에 특화해 분산을 2/nₙᵢₙ로 설정
- 편향(bias) 초기화: 보통 0으로 초기화하나 ReLU 계열에서는 0.01 정도의 작은 상수를 쓰기도 한다.
- 배치 정규화(Batch Normalization): 각 층의 활성화를 평균 0, 분산 1의 Gaussian 분포로 강제하여
초기화 민감도를 크게 완화한다.
정규화 기법 (Regularization)
정규화 기법에는 다음과 같이 있다.
- L2 규제(Weight Decay): 손실에 ½λ w² 항을 추가해 매개변수를 선형 감쇠시킵니다.
- L1 규제: λ |w| 항 추가 → 가중치 희소화 효과
- Elastic Net 규제 : L1 + L2 규제
- Max-norm 제약: 각 뉴런 가중치의 L2 노름을 c 이하로 클램핑(보통 c≈3~4)
- Dropout:
- 훈련 시: 확률 p로 뉴런을 유지(1–p 확률로 0) → 과적합 방지
- 테스트 시(inverted dropout): 훈련 단계에서 마스크에 1/p 스케일을 적용하여 테스트 단계 코드는 변경 없이 사용
손실 함수 (Loss Functions)
손실함수는 해결하려는 문제에 따라 다르게 적용한다.
- 분류(Classification)
- SVM 힌지 손실(왼쪽), 소프트맥스 교차 엔트로피(오른쪽)
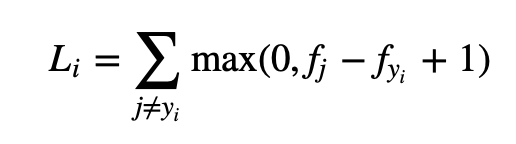

- 속성 분류(Attribute classification)
- 각 속성마다 이진 분류(힌지 또는 로지스틱)를 수행한다.
- 회귀(Regression)
- L2 손실(왼쪽), L1 손실(오른쪽)


- 구조화 예측(Structured Prediction)
- 구조적 SVM 등 특수 솔버 필요(여기서는 개념만 언급)
반응형
'학습 > AI' 카테고리의 다른 글
| Deep Learning for Computer Vision : Neural Networks 3 (1) | 2025.04.28 |
|---|---|
| Deep Learning for Computer Vision : Neural Networks 1 (0) | 2025.04.27 |
| Deep Learning for Computer Vision : Backpropagation, Intuitions (0) | 2025.04.27 |
| Deep Learning for Computer Vision : Optimization (0) | 2025.04.27 |
| Deep Learning for Computer Vision : Linear Classification (0) | 2025.04.25 |